Test-Time Adaptation for LLM Agents via Environment Interaction
Table of contents
📝 Authors
Arthur Chen, Zuxin Liu, Jianguo Zhang, Akshara Prabhakar, Zhiwei Liu, Shelby Heinecke, Silvio Savarese, Victor Zhong, Caiming Xiong
International Conference on Learning Representations (ICLR), 2026.
🔗 https://arxiv.org/abs/2511.04847
🚀 Overview
LLM-based agents can perform complex tasks like web navigation and function calling, but they often fail to generalize when deployed in new environments due to mismatches between their pre-training and the syntax (i.e., UI elements, input/output formats) and dynamics (i.e., environment transition rules) of the test-time environment. Annotated trajectories for LLM agents to learn to adapt to new environments is often not available or is too expensive to collect. This paper introduces grounded test-time adaptation (GTTA) techniques that allow agents to adapt during deployment – without annotations or expensive retraining – improving robustness and performance in unseen settings.
📌 Problem
LLM agents struggle in novel, interactive environments because:
- Syntax (e.g., UI elements, input/output formats) differs from training
- Dynamics (state transitions) are environment-specific and unpredictable
The goal is to enable test-time adaptation using only observations at test-time (i.e., after LLM model deployment), without supervision or labeled data
🧠 Key Contributions
Test-Time Adaptation Strategies
We propose two efficient adaptation strategies that operate during deployment and do not require annotated trajectories or heavy fine-tuning:
-
Syntactic Alignment
Learns a lightweight adaptation vector online that shifts the model’s output distribution to better match the environment’s syntax (e.g., UI labels). -
Dynamics Grounding
Performs a short persona-/goal-driven exploratory phase to extract environment dynamics, which are then summarized and used to inform subsequent agent decisions.
These strategies leverage only test-time interactions, without pre-collected annotated data or heavy fine-tuning.
🧩 Methods
🧠 Syntactic Alignment (SA)
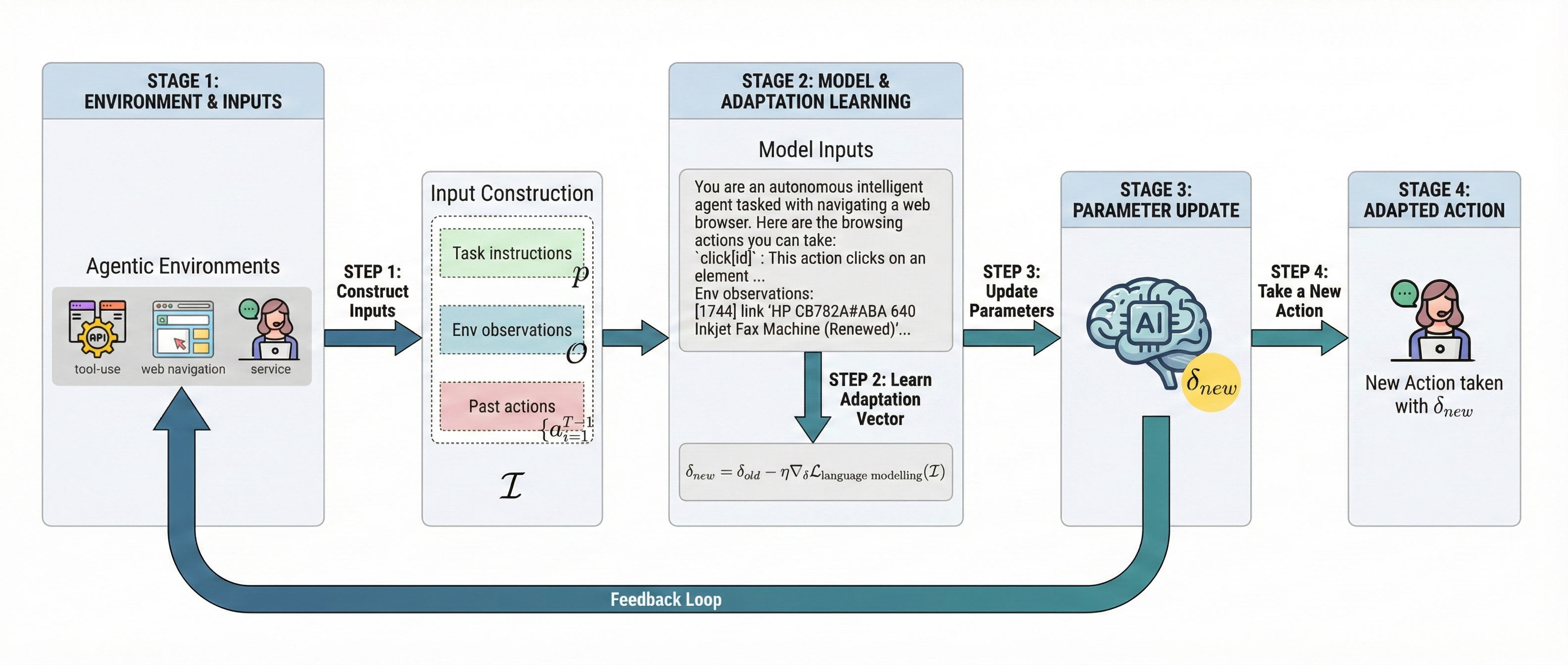 A four-step procedure adapts the LLM agent online via a lightweight adaptation vector:
A four-step procedure adapts the LLM agent online via a lightweight adaptation vector:
- Initialization: Create an adaptation vector at the beginning of each episode.
- Interaction: As the agent performs the task, it receives instructions and feedback from the environment.
- Update: After each move, update so the agent’s outputs better align with the environment’s style.
- Action Generation: Use the updated to help the agent generate improved actions as it continues.
🔎 Dynamics Grounding (DG)
A four-step pipeline builds an in-context world model of environment state transitions:
- Persona / Exploratory Goal Synthesis: Generate diverse goals to probe environment behaviors.
- Exploration & Logging: Execute exploratory actions to collect transition logs.
- Filtering & Consolidation: Remove trivial/repetitive rules.
- In-Context Augmentation: Integrate dynamics knowledge into the agent’s prompt.
This equips the agent with actionable causal insights into environment dynamics without supervised trajectories.
📊 Experimental Results
We evaluate GTTA across multiple agentic domains – Web navigation (WebArena), function calling (BFCLv3), and conversational agents (Tau-Bench):
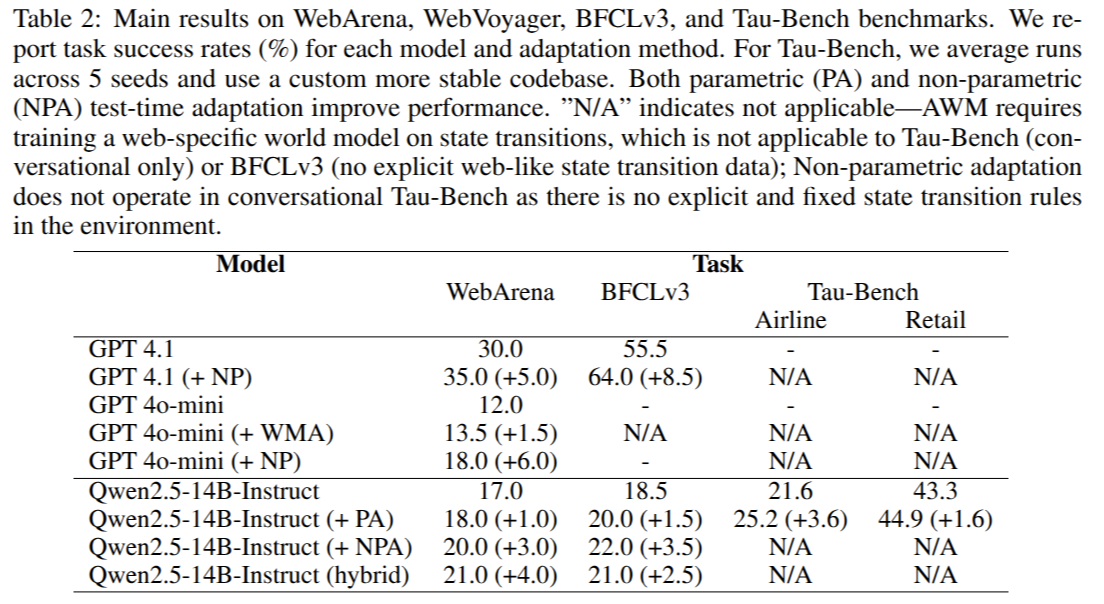
Analysis:
- Both adaptation strategies improve performance over static pre-trained baselines.
- Dynamics grounding shows especially strong gains in domains with complex transitions.
- E.g., on the WebArena multi-site (i.e., the agent must complete one task across multiple sites) split, success rates improved from ~2% → 23% with dynamics grounding.
📦 Why It Matters
This work provides:
- Deployment-time adaptation for LLM agents in unseen environments
- Methods are plug-n-play and don’t require annotations or heavy fine-tuning
- A practical path to more robust, generalizable LLM-based agents
It bridges the gap between static pre-training and dynamic, interactive real-world deployment.
📎 Resources
- 📄 Paper: https://arxiv.org/abs/2511.04847
- 📑 PDF: https://arxiv.org/pdf/2511.04847.pdf
- 🔗 Code: https://github.com/r2llab/GTTA
🙌 Acknowledgements
Work was performed during internship at Salesforce AI Research, supervised by Caiming Xiong and Victor Zhong. We thank all collaborators for their help and support.